【记录】尝试用R语言去抓取网页和提取信息
crifan 11年前 (2014-02-12) 10702浏览 3评论
【背景】 之前别人遇到问题: 用的是R语言,抓取一个特殊的网页: html中有两个charset <head> <meta http-equiv="Content-Type" content="te...
crifan 11年前 (2014-02-12) 10702浏览 3评论
【背景】 之前别人遇到问题: 用的是R语言,抓取一个特殊的网页: html中有两个charset <head> <meta http-equiv="Content-Type" content="te...
crifan 12年前 (2013-09-18) 4441浏览 0评论
【背景】 折腾: 【记录】用go语言实现模拟登陆百度 期间,搞懂基本的go的代码的写法和运行,接着就是去学习,如何用go实现基本的网页抓取的。 【折腾过程】 1.参考: 使用Go读取网页信息 去试试http.Get 2.期间,先去弄清楚,字符串初始化...
crifan 12年前 (2013-09-13) 3850浏览 1评论
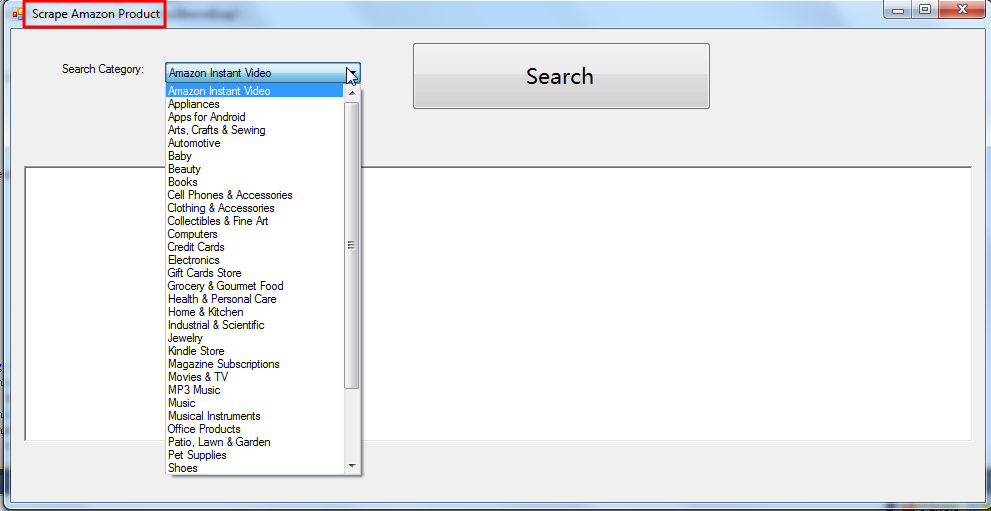
【背景】 之前写了个C#程序,从Amazon中抓取数据。 此版本是完全从网页中抓取产品信息的。 【ScrapeAmazonProduct代码分享】 1.截图: 2.完整项目代码下载: ScrapeAmazonProduct_2013-...
crifan 12年前 (2012-12-18) 5113浏览 0评论
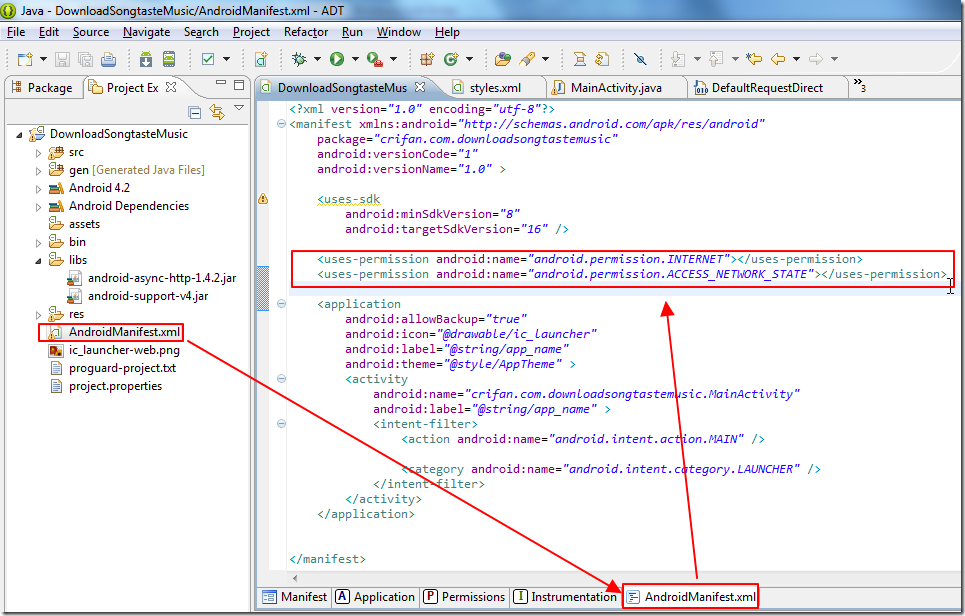
【问题】 之前已经实现了基本的Android的app的界面了,并且也可以获得从输入框中所输入的内容了: 【记录】实现安卓版的DownloadSongtasteMusic中的响应按钮点击 然后接着去要实现,在Android中,通过代码实现抓取对应的网...

crifan 12年前 (2012-12-08) 15416浏览 15评论
看此文之前,(强烈建议)先去看: 如何用Python,C#等语言去实现抓取静态网页+抓取动态网页+模拟登陆网站 然后,才明白,此文的作用和产生的背景。 其中,本文的部分内容,也会在上述帖子,给出额外链接,其中有更详细的解释的。 之前折腾了两个东...
crifan 13年前 (2012-11-23) 19347浏览 22评论
在通过: 【整理】关于抓取网页,分析网页内容,模拟登陆网站的逻辑/流程和注意事项 了解了抓取网页的一般流程之后,加上之前介绍的: 【总结】浏览器中的开发人员工具(IE9的F12和Chrome的Ctrl+Shift+I)-网页分析的利器 应该就很清楚如...