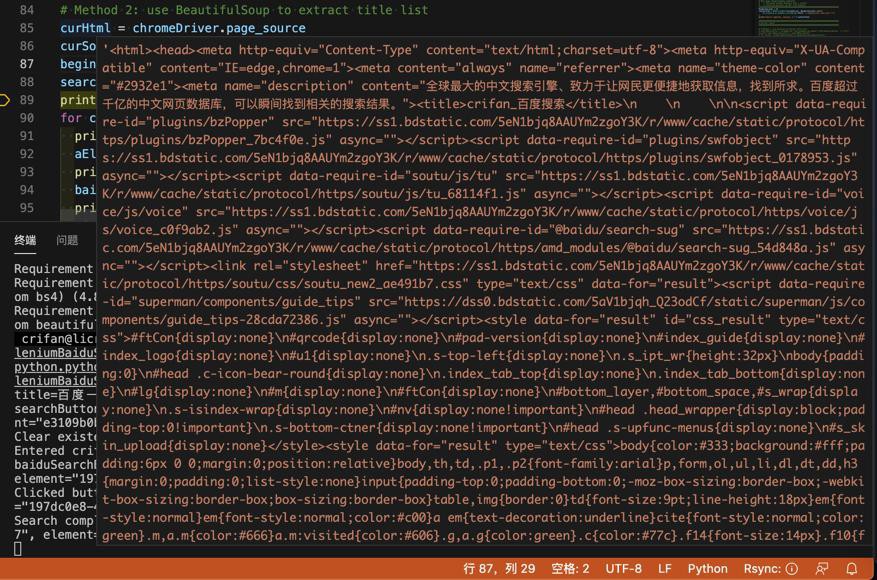
【已解决】Selenium中如何获取到当前页面的html源码
crifan 4年前 (2021-03-27) 5202浏览 0评论
折腾: 【未解决】Selenium中Python解析百度搜索结果第一页获取标题列表 期间,此处希望获取到Selenium的当前页面的html源码 Selenium get html python selenium get html Selenium ...
crifan 4年前 (2021-03-27) 5202浏览 0评论
折腾: 【未解决】Selenium中Python解析百度搜索结果第一页获取标题列表 期间,此处希望获取到Selenium的当前页面的html源码 Selenium get html python selenium get html Selenium ...
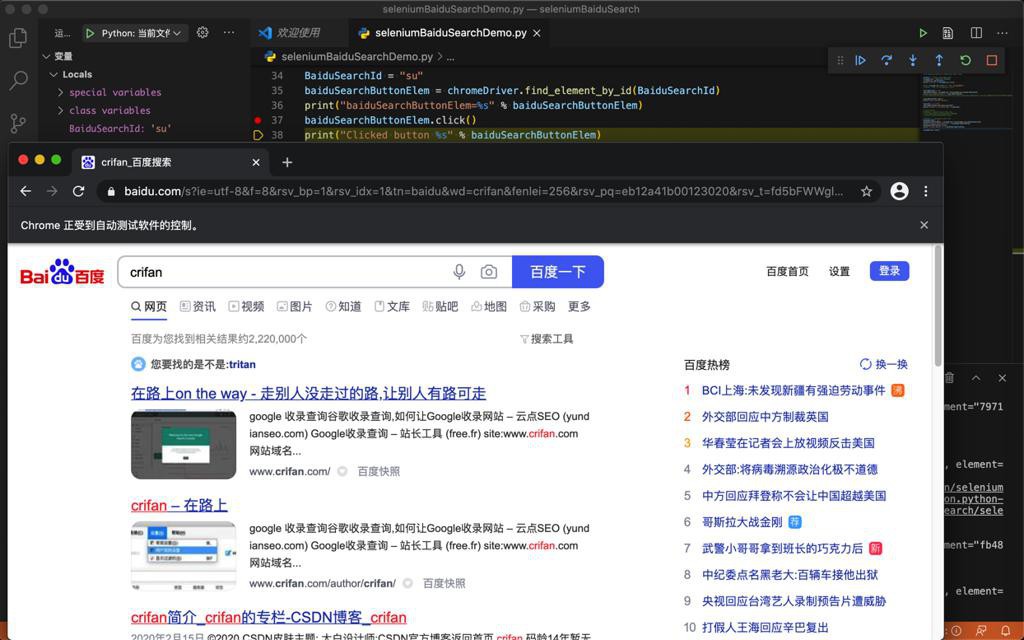
crifan 4年前 (2021-03-26) 1734浏览 0评论
折腾: 【未解决】Mac中用Selenium自动操作浏览器实现百度搜索 期间,已经用Selenium实现了百度首页的输入并搜索,显示出搜索结果了: 接下来,想办法实现,解析出搜索结果的标题的列表 此处尽量用多种方式去获取到最终结果,以演示如何写代码...
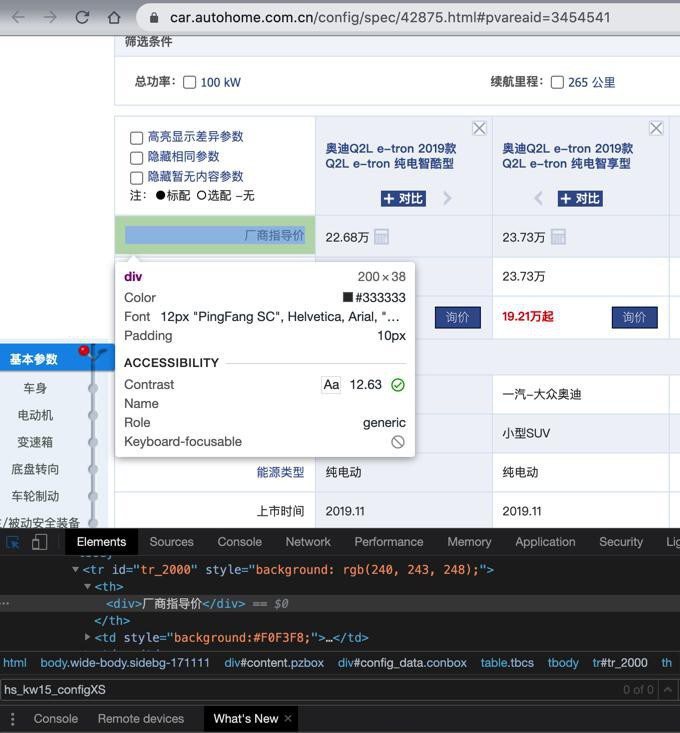
crifan 5年前 (2020-08-22) 2062浏览 0评论
折腾: 【未解决】汽车之家车型车系数据:抓取车型的详细参数配置 期间,发现虽然是直接返回了结果: var config = { "message": "<span class='hs_...

crifan 5年前 (2020-08-15) 2023浏览 0评论
折腾: 【未解决】用Python爬取汽车之家的车型车系详细数据 期间,希望从: 期间需要从: <ul class="rank-list-ul" 0> <li id="s3170&...
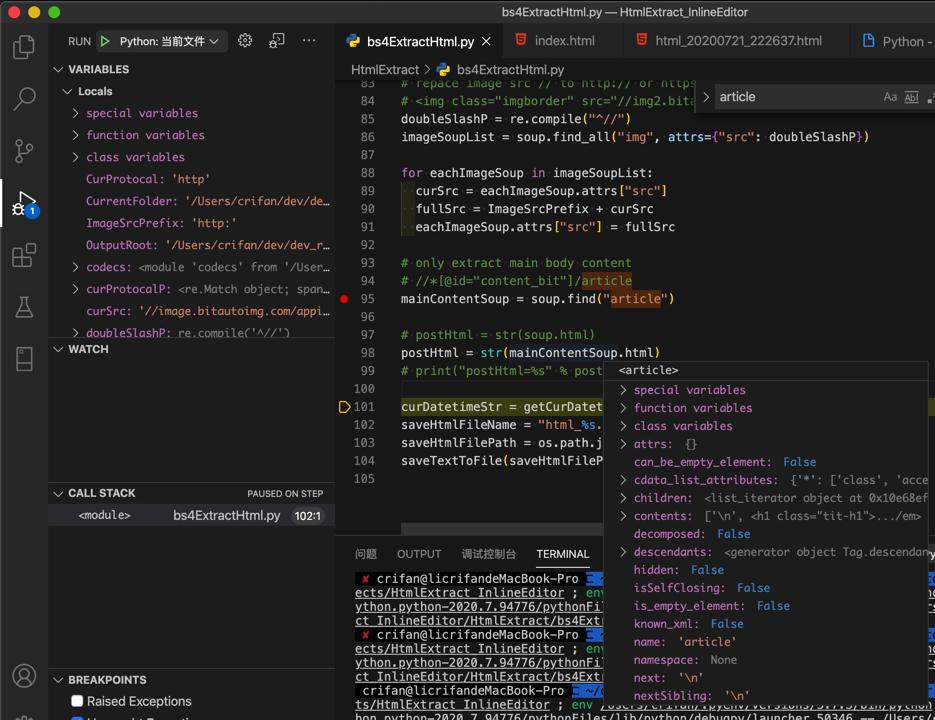
crifan 5年前 (2020-07-22) 1305浏览 0评论
折腾: 【已解决】Python的BeautifulSoup去实现提取带tag的HTML网页主体内容 期间,去写代码: # only extract main body content # //*[@id="content_bit"...
crifan 5年前 (2020-04-20) 1442浏览 0评论
折腾: 【未解决】爬取tch.ityxb.com中电子书《java 入门》 期间,去分析看看 找到最后的几个页面的逻辑: curl 'https://vip.ow365.cn/PW/GetPage?f=YXR0YWNobWVudC1j...
crifan 5年前 (2020-01-12) 3539浏览 0评论
折腾: 【未解决】java的com.iec.analysis.解析104出错:类型标识出错,无法解析信息对象 期间,需要去获取: int[] infoElement int startIdx = i * el...
crifan 5年前 (2020-01-09) 3770浏览 0评论
折腾: 【未解决】用Java代码解析104协议收到的数据 期间,再去实现for循环,从字符串数组中获取单个字符串。 java for string list java for loop string list How to iterate throu...
crifan 6年前 (2018-11-30) 5320浏览 0评论
折腾: 【记录】写脚本去加速处理已处理的7.3T数据 期间,需要用Python去获取: 文件的大小 文件夹的整个的大小 python get file folder size python – Getting File size from...
crifan 6年前 (2018-11-29) 1311浏览 0评论
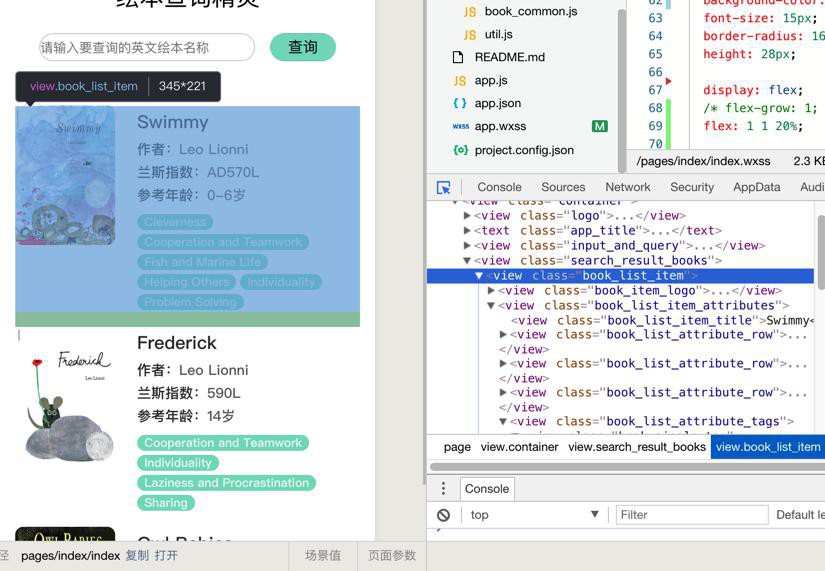
现在希望对于小程序: 列表中每行的整个区域,点击后,可以获取对应的此处该book的id 之前html中做法是html中加上个hidden的id,book的click的item中获取对应id 现在要去看看小程序中如何支持 先去加上点击事件 小程序...