【已解决】Scrapy的Python中如何解析部分的html字符串并格式化为html网页源码
crifan 7年前 (2018-03-05) 4454浏览 0评论
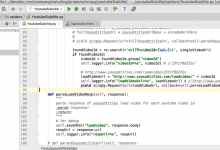
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,已经可以用scrapy去post某个url得到返回的部分的html的字符串了: {“id”:1637788,”title&#...
crifan 7年前 (2018-03-05) 4454浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,已经可以用scrapy去post某个url得到返回的部分的html的字符串了: {“id”:1637788,”title&#...

crifan 13年前 (2012-06-13) 3159浏览 0评论
想要实现在docbook中,引用另外某个xml文件中的一部分,并且是带参数,或者说实体定义的,这样被引用的xml中就可以实现动态内容的替换了。 首先,xinclude部分内容的需求,已经实现了: 【已解决】Docbook中,将section从chap...

crifan 14年前 (2011-11-16) 2455浏览 0评论
【未解决】360浏览器部分内容显示乱码 【背景】 安装了360浏览器 4.0正式版,在Win7 64bit的PC上,可以正常使用,但是部分内容出现乱码: 当前系统的IE浏览器是IE9: 【解决过程】 1.下载并安装了最...