【已解决】BeautifulSoup中find得到的soup节点如何获取自身及其下子孙节点的html源码
crifan 5年前 (2020-07-22) 1312浏览 0评论
折腾: 【已解决】Python的BeautifulSoup去实现提取带tag的HTML网页主体内容 期间,去写代码: # only extract main body content # //*[@id="content_bit"...
crifan 5年前 (2020-07-22) 1312浏览 0评论
折腾: 【已解决】Python的BeautifulSoup去实现提取带tag的HTML网页主体内容 期间,去写代码: # only extract main body content # //*[@id="content_bit"...
crifan 5年前 (2020-07-21) 1750浏览 0评论
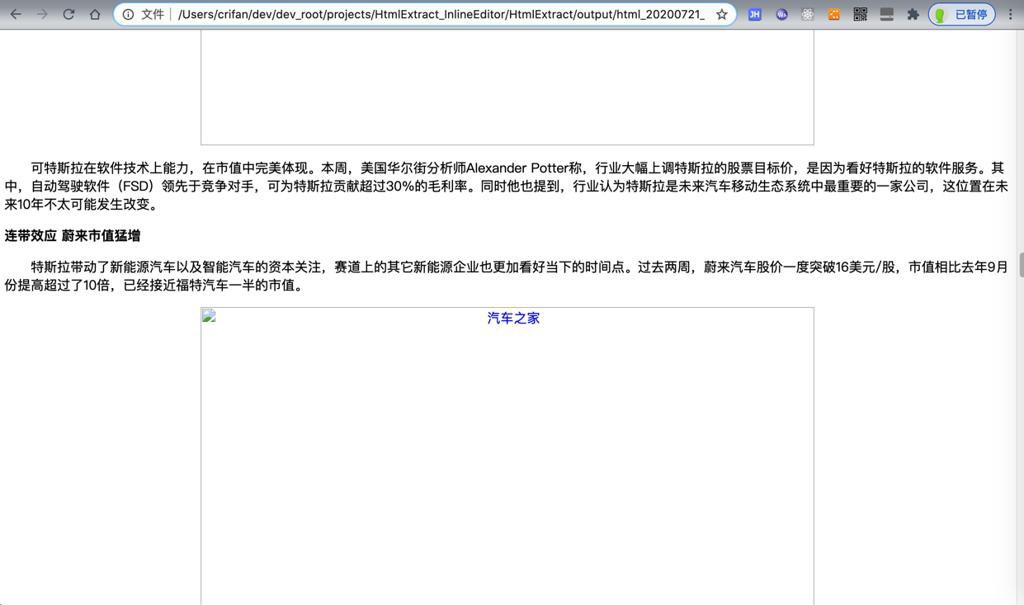
折腾: 【未解决】Python的BeautifulSoup去实现提取带tag的HTML网页主体内容 期间,用BeautifulSoup去导出html网页内容到本地,主体内容没问题。 但是图片无法显示: 只可惜图片无法显示。 去看看为何图片没显示...

crifan 12年前 (2013-10-17) 3009浏览 0评论
【问题】 python正则表达式的问题 的: <divclass="lib-cat"><h3>分类索引</h3><divclass="list"><...

crifan 12年前 (2013-09-09) 13804浏览 0评论
【背景】 是别人问我的: BeautifulSoup 4中,soup.string和soup.text何有区别。 【折腾过程】 1.去beautifulsoup的官网: bs3: http://www.crummy.com/software/Beau...
crifan 12年前 (2013-07-17) 11399浏览 3评论
table.mystyle { border-width: 0 0 1px 1px; border-spacing: 0; border-collapse: collapse; border-style: soli...
crifan 12年前 (2013-06-06) 5091浏览 5评论
【问题】 关于BeautifulSoup抓取目标数据的问题 本人在用BeautifulSoup抓到这些数据后(当然还有其他部分)不知道如何能够用BeautifulSoup的解析方法(用re好像很复杂)去提取我想要的24,804,000,000...
crifan 12年前 (2013-05-30) 11049浏览 0评论
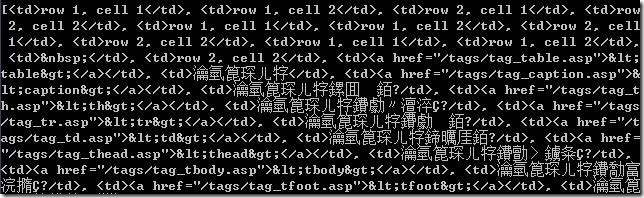
【问题】 某人遇到的问题: 关于BeautifulSoup抓取表格及SAE数据库导入的问题(跪求大神帮忙) 简单说就是: 用如下代码: import re,urllib2 from BeautifulSoup import BeautifulSou...
crifan 12年前 (2013-04-19) 8798浏览 1评论
【背景】 折腾过基本的BeautifulSoup的人,知道,可以通过指定对应的name和attrs去搜索,特定的名字和属性,以找到所需要的部分的html代码。 但是,有时候,会遇到,对于要处理的内容中,其name或attr的值,有多种可能,尤其是符合...
crifan 12年前 (2013-02-01) 10824浏览 3评论
背景 在Python去写爬虫,网页解析等过程中,比如: 如何用Python,C#等语言去实现抓取静态网页+抓取动态网页+模拟登陆网站 常常需要涉及到HTML等网页的解析。 当然,对于简单的HTML中内容的提取,Python内置的正则表达式Re模块,就...
crifan 13年前 (2012-11-23) 9423浏览 5评论
【BeautifulSoup最简介】 BeautifulSoup,是Python中的一个第三方库,用于帮助解析Html/XML等内容,便于实现后期的内容提取等方面的工作。 BeautifulSoup官网地址:http://www.crummy.com...