【已解决】PySpider中用PyQuery提取出html中p下面的a的href中的多个strong字符串
crifan 7年前 (2018-10-11) 1147浏览 0评论
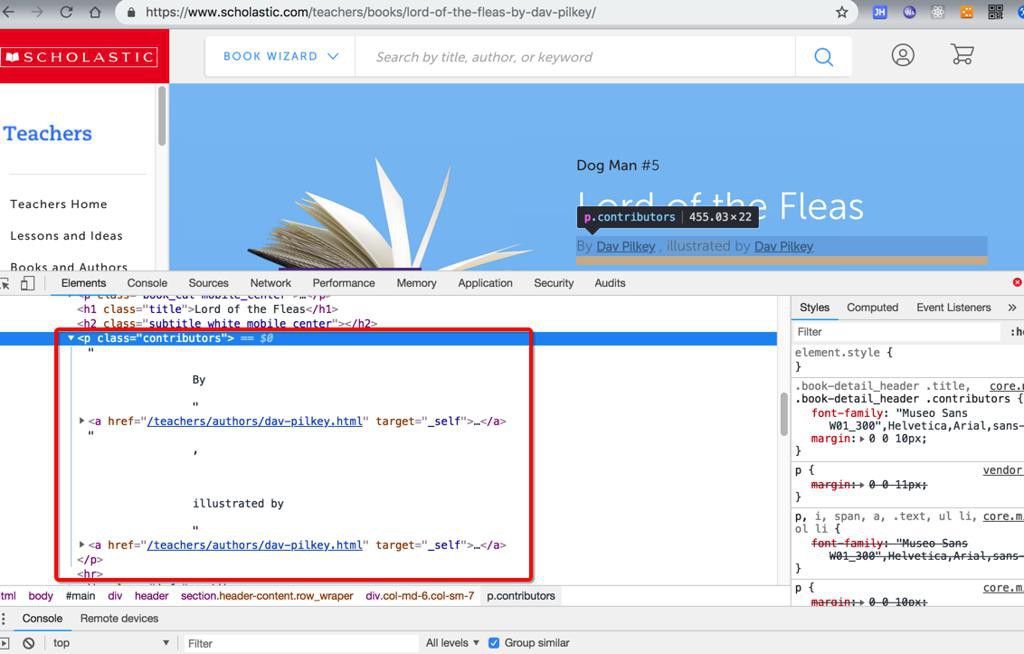
折腾: 【记录】用PySpider去爬取scholastic的绘本书籍数据 期间,遇到一个稍微特殊一点的内容的提取: https://www.scholastic.com/teachers/books/lord-of-the-fleas-by-dav...
crifan 7年前 (2018-10-11) 1147浏览 0评论
折腾: 【记录】用PySpider去爬取scholastic的绘本书籍数据 期间,遇到一个稍微特殊一点的内容的提取: https://www.scholastic.com/teachers/books/lord-of-the-fleas-by-dav...
crifan 7年前 (2018-03-06) 3110浏览 0评论
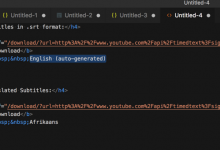
折腾: 【已解决】Scrapy的Python中如何解析部分的html字符串并格式化为html网页源码 期间, 对于: <code><h4>Subtitles in .srt format:</h4...
crifan 7年前 (2018-01-13) 6024浏览 0评论
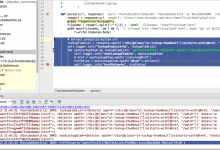
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,对于scrapy的response的xpath得到的Selector,如何获取其中的a中href的值 Scrapy 1.5 documentation — Scr...