【记录】用Python从pdf文件中提取文字数据信息
crifan 12年前 (2013-05-20) 6228浏览 0评论
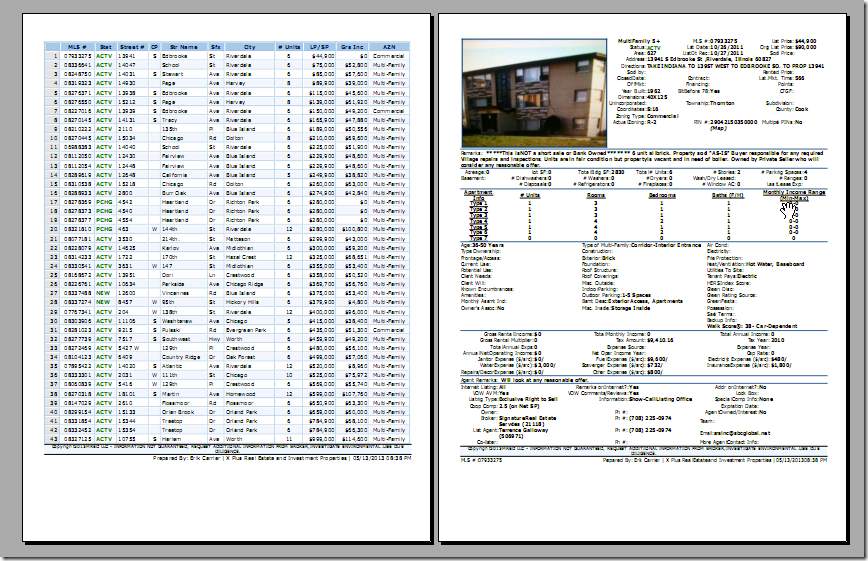
【背景】 已有一个pdf文件,效果如下: 想要用python从中提取一些信息。 【折腾过程】 1.搜了下,找到个: pyPdf http://pybrary.net/pyPdf/ 其功能之一是: “extracting document infor...
crifan 12年前 (2013-05-20) 6228浏览 0评论
【背景】 已有一个pdf文件,效果如下: 想要用python从中提取一些信息。 【折腾过程】 1.搜了下,找到个: pyPdf http://pybrary.net/pyPdf/ 其功能之一是: “extracting document infor...

crifan 12年前 (2013-04-13) 4173浏览 4评论
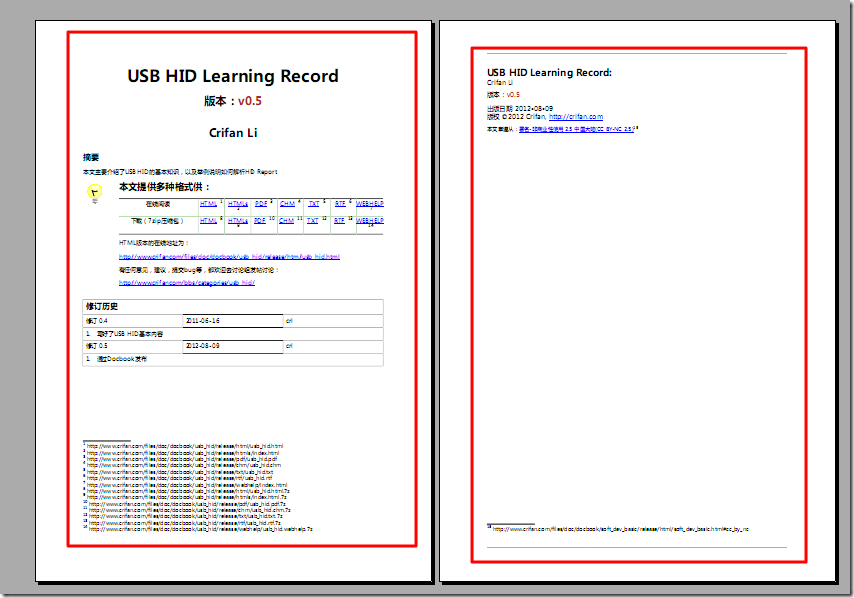
【问题】 希望将docbook生成的pdf中,每页都添加上对应的边框。 就像这样的: 【解决过程】 1.这里: Top and bottom margins 倒是介绍了,页面的结构组成。 2.参考: Borders 给chapter添加frame:...
crifan 12年前 (2013-04-13) 2467浏览 0评论
【背景】 docbook生成的pdf,默认都有前两页的那个titlepage: 想要去掉。 【解决过程】 1.找了半天,貌似官网的这部分: Custom page design 的介绍,是相关的内容。 2.找到对应的 docbook-xsl-ns-...

crifan 13年前 (2012-08-14) 2352浏览 0评论
【问题】 docbook源码写好了,可以正常编译为html。 也可以编译为fo了,但是使用fop从fo中生成pdf却出错: 严重: Exception org.apache.fop.apps.FOPException: -1 ...

crifan 13年前 (2012-06-28) 3868浏览 2评论
【问题】 docbook中,默认所生成的book的文章标题和目录,是不同的页(page)中显示的: 此处需要实现将标题和toc在同一页显示,就像这样: 【解决过程】 1.找到官网中关于toc的介绍: Tables of...

crifan 13年前 (2012-06-05) 4195浏览 0评论
【问题】 docbook的源码中包含了emphasis的部分: <sect2><title>什么是ISO/IEC 11172-3和ISO/IEC 13818-3</title> <pa...

crifan 13年前 (2012-06-05) 3563浏览 0评论
【问题】 已经实现了去掉带链接的文字后面的url链接,但是想要pdf中的带链接的文字,都像html中的一样,颜色为蓝色,且带下划线。 即,pdf中是这样的: 想要实现html中的这样的效果: 【解决过程】 1.折腾这个: 【已解决】去掉docbo...

crifan 13年前 (2012-06-05) 2580浏览 0评论
【问题】 已经可以成功用docbook生成pdf中,包含revhistory所对应的历史版本部分的内容了,但是所显示出来的表格,没有边框,效果如下: 现在希望输出的pdf中,该修订历史部分的表格,是有边框的,就像之前用word生成出来的效果一样: ...

crifan 13年前 (2012-05-31) 2710浏览 0评论
【问题】 已经用xsltproc+fop实现了callout,在PDF和HTML中都可以正常显示了。 详见:【已解决】Docbook中的callout图片在programlisting中不显示 -> xsltproc不支持areaspec 但是...

crifan 13年前 (2012-05-29) 2851浏览 0评论
【问题】 Docbook的pdf中, 正常表格式是这样的: 但是当表格在quote中的时候,就变成这样了: 即表格的头部header跑到底端了。 而且,如果单个entry的内容是多行的话,结果还会显示出多行: 所以,整个显示都是完全乱套了。 【...