【记录】尝试使用pdftohtml将不可拷贝的PDF文件转换为HTML并保留表格的格式
crifan 11年前 (2014-01-27) 4524浏览 0评论
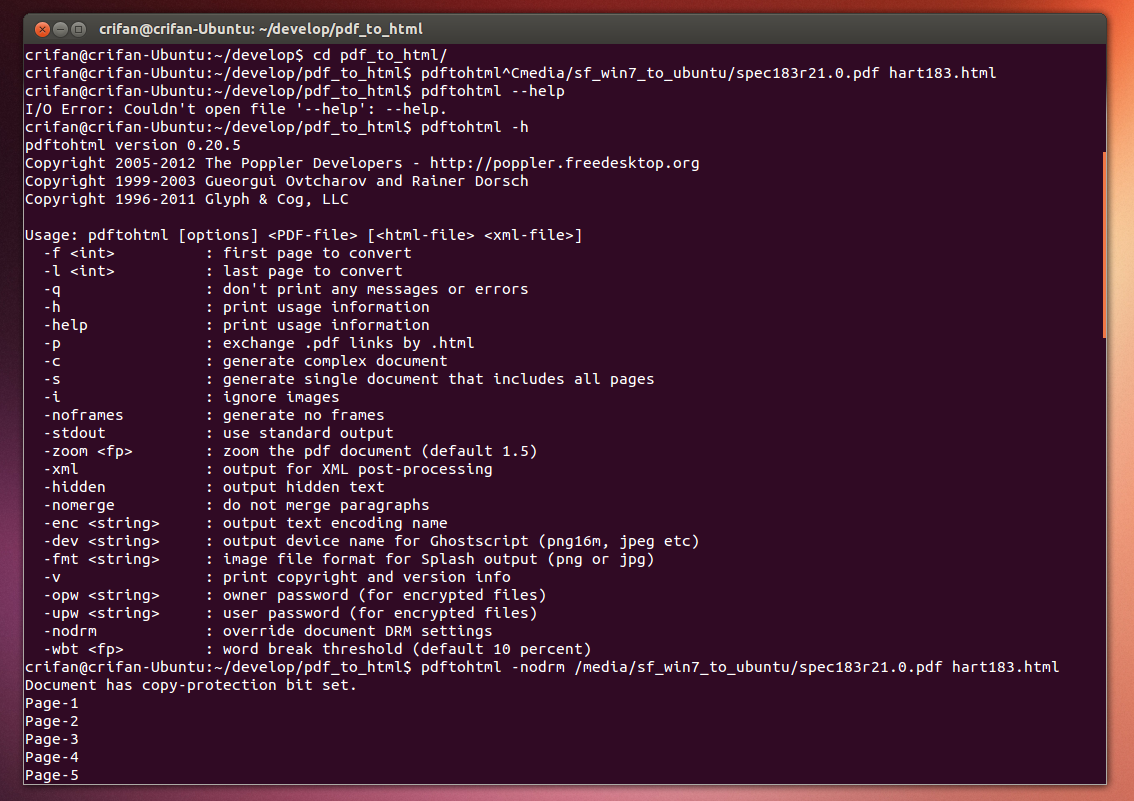
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,去试试用pdftohtml,将一个不可拷贝的pdf文件,转换为文本或html。 【折腾过程】 1.继续参考: Howto Convert P...
crifan 11年前 (2014-01-27) 4524浏览 0评论
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,去试试用pdftohtml,将一个不可拷贝的pdf文件,转换为文本或html。 【折腾过程】 1.继续参考: Howto Convert P...

crifan 11年前 (2014-01-27) 3262浏览 0评论
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,去试试用xpdf,将一个不可拷贝的pdf文件,转换为文本或html。 【折腾过程】 1.参考: PDFTOHTML conversion p...
crifan 11年前 (2014-01-27) 3418浏览 0评论
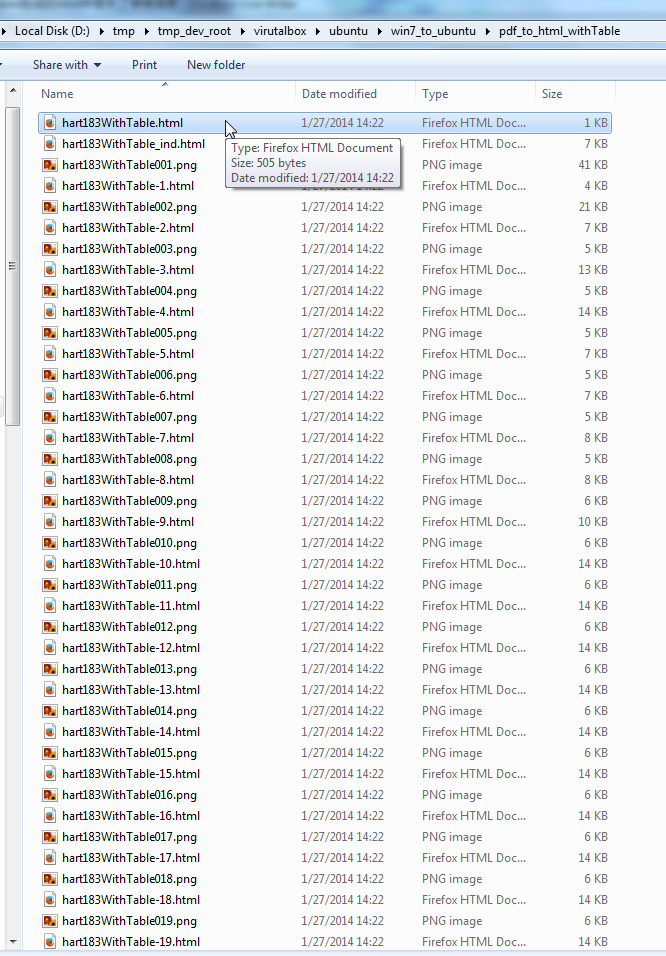
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,虽然可以用pdftohtml通过加-nodrm参数而使得将不可复制的pdf生成html。 但是生成的html中,丢失了原先pdf中有个那些表格的数据,只剩...