◆人体听觉心理学模型
下面将简要介绍一下几个重要原理:
1) 最小听觉门槛判定(The minimal audition threshold):人耳的听力范围是20Hz-20k Hz的频率范围,但是人耳对不同的频率声音的灵敏度是不同的,不同频率的声音要达到能被人耳听到的水平所需要的强度是不一样。那么通过计算,可以把音乐文件中存在但不能被人耳听到的声音去掉。 通过这原理,我们还可以建立模型,把大部分数据空间分配到人耳最灵敏的2kHz到5kHz范围,其余频率分配比较少的空间;
2) 人耳的遮蔽效应(The Masking effect): 蔽效应表现在强信号会遮蔽邻近频率的弱信号。用生活经验来说,在安静的房间中,一根针掉到地上都能听见,可到了大街上,就算手机音量调到最大,来电时也未必能听见,而手机的声音确确实实是存在的,原因就是被周围更大的声音遮蔽了。有了对遮蔽效应的研究成果,编码器就能根据已建立的数学模型,计算强信号对附近弱信号的遮蔽,把能引起人们注意的声音才保留。
人耳还有前遮蔽效应和后遮蔽效应:因为人需要一定的时间来处理声音信号,在强信号之前或之后的弱信号,会被遮蔽掉。前遮蔽效应的时间约只有2-5ms,而后遮蔽的时间比较长,大约有100ms。利用这,我们能减小强信号之前和之后的分辨率;
3) 人耳的空间响应: 人耳对某些高频的声音的空间感很差,辨别不了声源的方向。联合立体声(Joint Stereo)应运而生:在某些频率上采用“单声道”(事实上并非真正意义上的单声道),以减小流量。
◆VBR技术
正如上面所说,MP3是由帧构成的,MP3能象动画那样读到哪放到哪, 播放器不必预读整个文件的内容,即使部分数据损坏也不会对播放效果有太大影响(实际上这就是流媒体所具有的特性)。而每个帧的帧头里都包含这该帧的码率(bitrate,单位是kbps)等信息,所以,我们可以对每一段音乐甚至每一个帧定义独立的码率,这就是VBR(Variable bitrate,动态码率)技术。
与VBR向对应的是CBR(Constant bitrate)。一支交响曲,合奏大动态部分的数据量显然大于引子部分,如果用128kbps的CBR编码方式来编码,在引子部分可能有多余的数据流量,而在合奏部分却又不够,VBR就是解决这个问题的。把在不影响音质的情况下,对流量需求小的部分分配较小的码率,把冗余字节缓存起来留给有需要的部分,在短时间内提供更高的码率,以保证音乐的质量。
所以说,VBR的作用是更合理的分配流量,在不增大文件体积的条件下提高声音的质量。
不过VBR在应用初期带给过MP3随生听不少麻烦。因为早期大多数MP3播放器都是针对CBR设计的,其根据文件大小来获得时长的算法对VBR失效了,因为VBR MP3的bitrate可能每时每刻都在变化。不过现在这个问题基本上不用担心了,市场上的播放器基本上都解决这问题了。
除了上面说的两方面,MP3编码还有很重要的一招:Huffman编码(Huffman是个科学家的名字), Huffman编码广泛应用于无损压缩领域,比如我们常用的WINZIP,WINRAR等压缩软件就是以此为基础的(只能说是基础,因为这些用到的编码方法不只是Huffman编码)。 Huffman编码用途就是降低数据的冗余度,可节省大约20%的空间。用WINZIP来再压缩MP3文件每什么效果就因为MP3编码的时候已经应用到采用Huffman编码。
■深入了解
上面简单介绍了MP3的编码原理,下面那我们将深入看看编码器是怎样工作的。
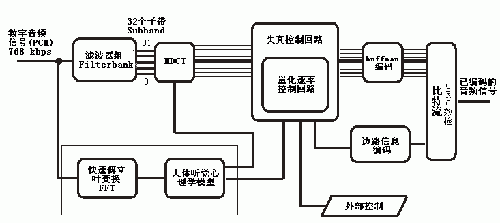
&picid=132023.GIF){kind=link}
(MP3编码器结构图,点击放大)
1) 滤波器段(filterbank)
数字音频信号以脉冲的形式送进编码器,首先会经过一滤波器段(filterbank),它由两个串联的滤波器段组成:一个多相分析滤波器段和一个MDCT(Modified Discrete Cosine Transform,经改良的离散余弦转换),前者也应用到layer-1和layer-2中,后者是MP3独有的。
输入的音频信号在20Hz-20k Hz的频率范围内,通过第一个滤波器段后,把信号按频率分成32个小频带,称为子带(Subband)。20000Hz/32=625Hz,那么每个子带的宽度就是625Hz。人耳对不同频段的灵敏度是不同的,编码器可对不同的子带进行不同的量化分层。
不过等宽的子带并没有准确反映人耳的听觉特性,这样进行等宽划分并没有考虑到不同信号的临界宽度,也就是该信号的影响范围,以及不同信号的相互影响,所以这样会产生大量的信号重叠。MDCT转换就是为了解决这问题,它能对子带进行细分,清楚重叠部分,得到更高的频谱解析度。
2) 人体听觉心理学模型(Perceptual Model)
上面已经谈到过人体听觉心理学模型,心理学模型可以说是感受编码的重中之中,它决定着编码器的编码质量(后面谈到的LAME就拥有着大量优秀的人体精神听觉模型和数学模型)。下面将深入分析两个重要原理: 最小听觉门槛判定和遮蔽效应。
◆最小听觉门槛判定
声音其实是传播在介质中的能量波,人耳对声音能量强弱的直接感受就是听到音量的大小,也就是响度,单位是分贝(dB)。下面是人耳可听最小响度曲线:
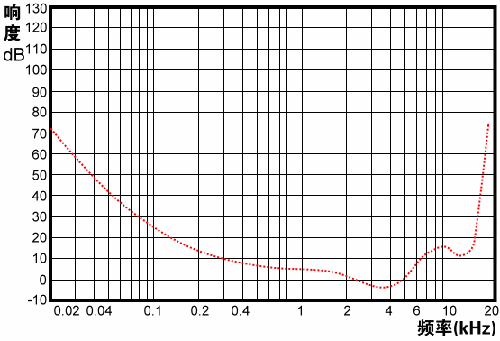
(0dB是听觉灵敏度的极限,而120dB是痛苦灵敏度的极限。人耳在2000Hz到5000Hz范围内的灵敏度最高,两端就迅速下降。所以人耳对中频的灵敏度远高于高低频。)
◆遮蔽效应
不同频率的声音有不同的遮蔽宽度,这叫临界宽度。可以想象,弱信号越接近强信号的中心,遮蔽效应会越严重。临界宽度跟声音频率成正比。下面是临界宽度列表:
频率(Hz) | 临界带宽(Hz) | 频率(Hz) | 临界带宽(Hz) |
50 | 80 | 1850 | |
2150 | |||
350 | 380 | ||
450 | 3400 | 550 | |
570 | 120 | 4000 | |
700 | 140 | 4800 | |
840 | 150 | 5800 | 1100 |
160 | 7000 | 1300 | |
1170 | 190 | 8500 | 1800 |
1370 | 10500 | ||
1600 | 240 | 13500 | 3500 |
感受编码机制可以分为两个部分:知觉噪音成型(perceptual noise shaping)和知觉边带/变换编码(perceptual subband / transform coding)。编码器通过分析滤波器段(filterbank)分析音频信号的频谱组成并应用听觉心理学模型来估计仅仅可以注意得到的噪音电平。在后面的量化和编码阶段,编码器会提高强信号附近的噪音电平,也就是减少量化位数,这样就能达到节省流量,压缩数据的目的。如果所有量化噪音都能控制在屏蔽临界曲线以下,那么处理后人耳就区别不出哪个才是原音。
3) 量化和编码(Quantization and Coding)
当PCM讯号被分成好几个频段并经过一系列的处理后,最后经过MDCT,将波型转换为一连串的系数。这些系数就由Huffman编码器会选择最合适的Huffman表来做最后的压缩。 Huffman编码一般是双路工作的,但是在某些需要精密编码的情况下,它会进行四路工作。编码器一般会有很多的Huffman编码表,很多时候为了更好的声音质量和更有效屏蔽量化噪音,编码器甚至能为每一个频段选择最合适的Huffman编码表。
不过编码不是一次就能成功的,要采取Try and Error的方式循环进行。因为编码器一方面要削减量化噪音,让它在人耳遮蔽曲线以下;另一方面要保证bitrate满足要求。实际上这里就是要确定两个数值:一个是确定bitrate的步进值(gain value),另一个是削减量化噪音的增益因子(ScaleFactor),这两个系数会在正式编码之前确定下来,确定过程由两个嵌套的迭代回路完成:失真控制回路(Distortion Control Loop)和量化速率控制回路(Nonuniform Quantization Rate Control Loop)
<内部迭代回路(Rate Loop )>
量化以后的数据送进Huffman编码器,当发现比特数大于可用流量时,编码器会返回信息,让Rate Loop调整步进值以增大量化步长,从而让数据流量减小。循环会一直进行,尝试不同的量化步长,直到Huffman编码以后的数据流量足够小。因为这个回路是用来控制码率的,所以叫做Rate Loop。
<外部迭代回路(noise control loop)>
显然,这个回路的作用就是控制量化噪音(quantization noise),让其保持在听觉心理学提供的屏蔽临界线(masking threshold)以下。每一个频段都会有一个增益因子,一开始编码器以1。0作为默认因子,如果量化噪音量超过允许的值,那么回路就会调整增益因子,来把量化噪音降下来。更少的量化噪音意味着流量增大,码率需要提高,所以增益因子每次改变以后, Rate Loop都要进行调整,让码率符合要求。
所以两个回路是嵌套工作的,互相协调,中止条件是量化噪音降到屏蔽临界线以下而码率也足够小。良好的编码器会让两个回路有条不紊的工作,因为一旦处理不好就很容易陷入死循环。
2.1.2 解码
MP3文件帧组成,每个帧又由帧头和帧数据组成。帧头长4字节。其数据结构如下:
typedef struct _tagHeader
{
unsigned int sync:12; file://同步信息
unsigned int version:1; file://版本
unsigned int layer:2; file://层
unsigned int error_protection:1; file://CRC校正
unsigned int bit_rate_index:4; file://码率索引
unsigned int sample_rate_index:2; file://采样率索引
unsigned int padding:1; file://空白字
unsigned int extension:1; file://私有标志
unsigned int channel_mode:2; file://立体声模式
unsigned int mode extension:2; file://保留
unsigned int copyright:1; file://版权标志
unsigned int original:1; file://原始媒体
unsigned int emphasis:2; file://强调方式
} HEADER, *LPHEADER;
在帧头后边是通道信息和增益因子(ScaleFactor),数据以比特流的形式送进编码器,当解码器在读到上述信息后,就可以进行解码了。解码比编码容易得多,播放器先进行帧同步,然后读取通道信息和增益因子,再进行Huffman解码,这样就得到解压以后的数据。但这些数据仍然不能进行播放,因为它们还只是一些频段信息,还需要经过特殊手段对他们转换组合,跟时间建立联系(实际上就是频域转时域)。然后进行一系列的逆变换,把音频信号重建出来。
前面说的是软解码,现在来谈谈硬解码,也就是现在很流行的MP3随身听。 它的工作流程一般是这样的:读取存储器上的数据(存储器可能是闪存,硬盘或光盘)→把数据送进解码芯片进行解码→通过数模转换器将解出来的数字信号转换成模拟信号-→再把转换后的模拟音频放大-→低通滤波后到耳机输出口。
也就就是说解码的主要任务交给了解码芯片。MP3的芯片分为单芯片和双芯片,单芯片设计就是把控制部分,MP3解码部分等都集成到一块芯片中;双芯片就是把控制部分和MP3解码部分分开。随着集成电路的发展,厂商都倾向于使用单芯片设计,而提供芯片的厂家就那么几家,所以,不同品牌的MP3播放器中,很大程度上决定回放质量的解码芯片可能是一样。
早期有不少MP3播放器不支持高于224kbps的MP3,这也是芯片惹的祸。VCD里的音频使用的是MP2格式(MPEG-1 Audio Layer2),所以不少MP3厂家为了节省成本,简化VCD的解码芯片用作MP3解码芯片,而VCD规范中音频流量最高是224kbps,问题由此产生。不过现在这中问题基本不存在了。
转载请注明:在路上 » 打造发烧音质:MP3音频完全攻略(上)-2 [ZT]