需要把文本格式的:
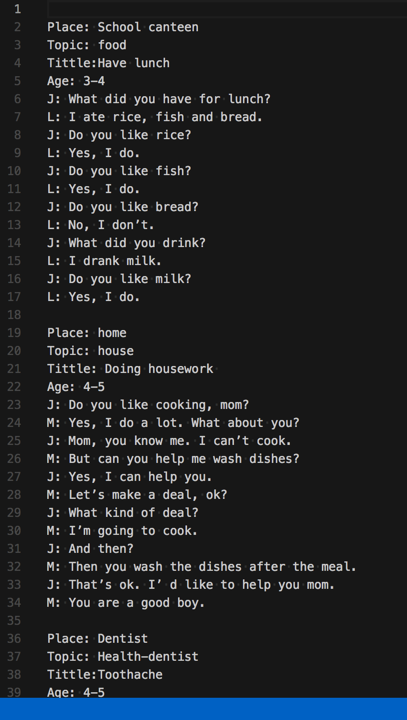
已编写的对话剧本
去用Python脚本处理,实现批量导入到系统中
而原本是手动的录入到系统中的:
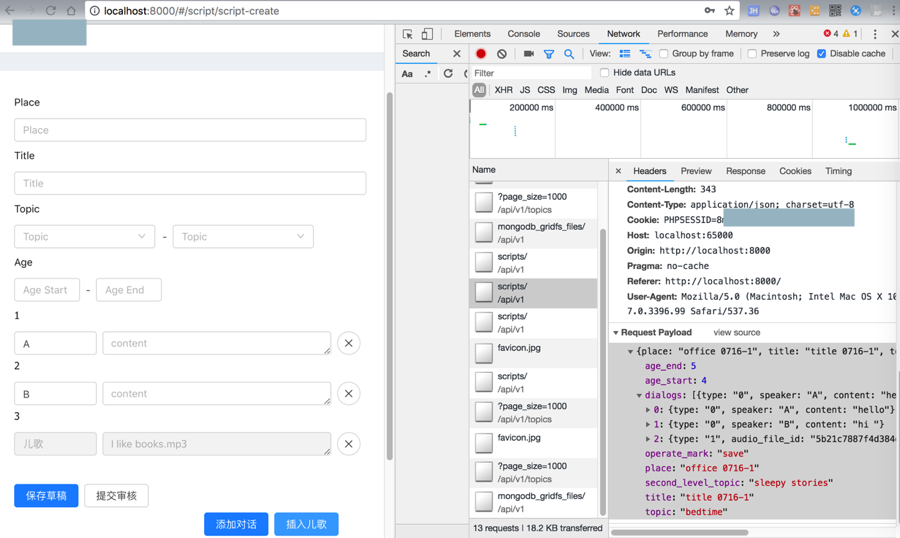
所以去搞清楚
调用了后台的接口是:
1. Request URL:
http://localhost:65000/api/v1/scripts/
2. Request Method: POST
1. age_end:5
2. age_start:4
3. dialogs:[{type: "0", speaker: "A", content: "hello"}, {type: "0", speaker: "B", content: "hi "},…]
1. 0:{type: "0", speaker: "A", content: "hello"}
2. 1:{type: "0", speaker: "B", content: "hi "}
3. 2:{type: "1", audio_file_id: "5b21c7887f4d384d04535fe2", audio_file_name: "The Tunnel.mp3"}
4. operate_mark:"save"
5. place:"office 0716-1"
6. second_level_topic:"sleepy stories"
7. title:"title 0716-1"
8. topic:"bedtime"
对应web端源码是:
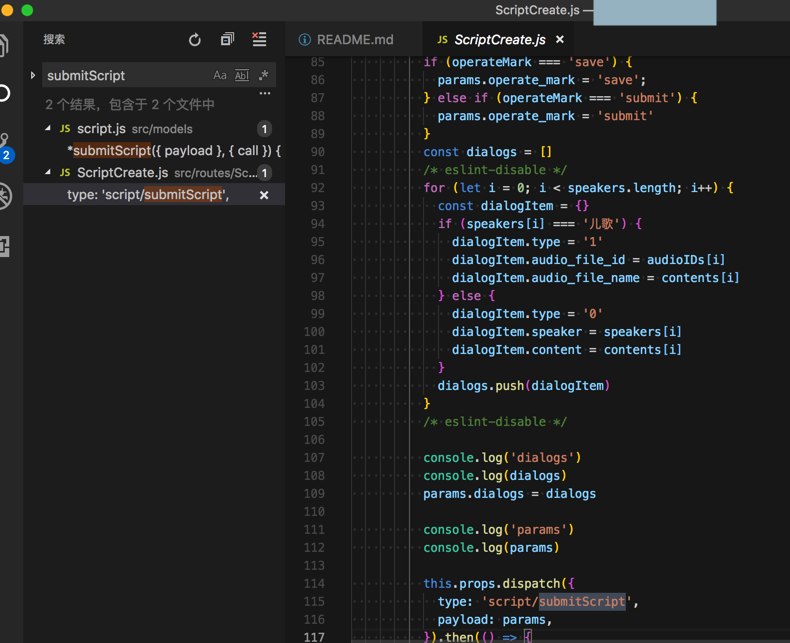
后台源码是:
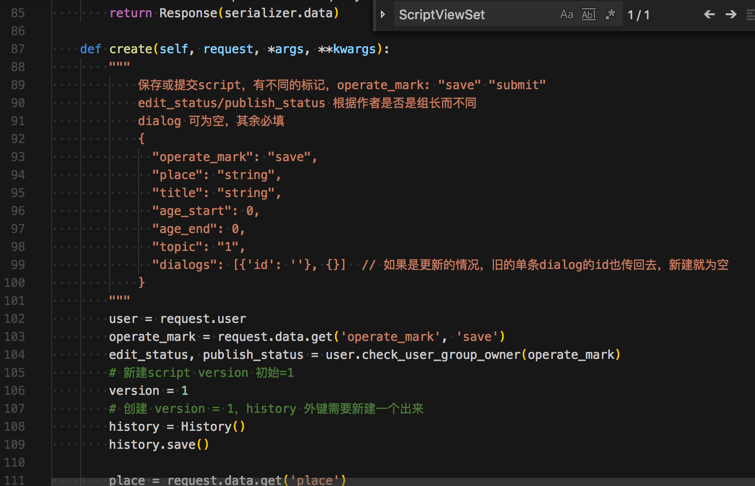
然后现在需要:
先去用Python处理识别出来具体的每个script的内容
然后再去调用接口去POST创建。
然后接着去:
用数据结构dict去保存起来,再去调用后台API,且POST之前看来也要去获得token
然后期间需要:
【已解决】python中判断单个或多个单词是否是全部小写或首字母小写
为了能够调用后台系统的api,然后接着需要去搞清楚如何用户登录和传递JWT的token:
【已解决】Python中如何模拟用户登录和传递JWT的token以获取访问API的权限
然后调用保存接口时出错:
【已解决】Python调用接口出错:TypeError string indices must be integers
接着又出现其他错误:
【已解决】Python接口返回400错误:{‘detail’: ‘JSON parse error – Expecting value: line 1 column 1 (char 0)’}
然后接着要去解决:
【总结】
最后用如下代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-07-11 14:12:12
# Project: BatchImportScript
# Function: Batch process witten script content from txt into Naturling CMS system
# Author: Crifan Li
# Updated: 20180717
import os
import re
import logging
import requests
import sys
currentPath = os.path.split(os.path.realpath(__file__))[0]
crifanlibPath = os.path.abspath(os.path.join(currentPath, "crifanLib"))
sys.path.append(crifanlibPath)
from crifanLib import crifanMysql, crifanFile, crifanLogging
################################################################################
# Global Config
################################################################################
# is online/production or local debug environment
IsOnline = True
################################################################################
# Global Settings / Variables
################################################################################
ScriptFolder = "input"
ScriptFilenameList = [ "person_1.txt", "person_2.txt"]
# # for debug
# ScriptFilenameList = ["person_2.txt", "person_1.txt"]
MysqlConfigDict_Local = {
‘host’: "localhost",
‘port’: 3306,
‘user’: "root",
‘password’: "crifan_mysql",
‘db’: "naturling",
‘charset’: "utf8",
}
MysqlConfigDict_Online = {
‘host’: "xxxxxx",
‘port’: 3306,
‘user’: "root",
‘password’: "pwd",
‘db’: "naturling",
‘charset’: "utf8",
}
MysqlConfigDict = None
if IsOnline:
MysqlConfigDict = MysqlConfigDict_Online
else:
MysqlConfigDict = MysqlConfigDict_Local
gTopicDict = {}
UserInfoDict = {
"wuman" : {
"username": "user1",
"password": "pwd1",
},
"zhouyue" : {
"username": "user2",
"password": "pwd2",
},
}
ApiHost = None
if IsOnline:
ApiHost = "http://x.x.x.x"
else:
ApiHost = "http://localhost"
Port = 65000
ApiVersion = "/api/v1"
ApiPrefix = ApiHost + ":" + str(Port) + ApiVersion # http://localhost:65000/api/v1/
GetJwtTokenUrl = ApiPrefix + "/jwt-token-auth/" # http://localhost:65000/api/v1/jwt-token-auth/
CreateScriptUrl = ApiPrefix + "/scripts/" # http://localhost:65000/api/v1/scripts/
gJwtToken = ""
gHeaders = {
‘Content-Type’: ‘application/json; charset=utf-8’,
"Accept": ‘application/json’,
"Authorization": "",
}
################################################################################
# Functions
################################################################################
def updateTokenAndHeader(userInfo):
global gJwtToken, gHeaders
postBody = {
"username": userInfo["username"],
"password": userInfo["password"],
}
logging.info("GetJwtTokenUrl=%s, postBody=%s", GetJwtTokenUrl, postBody)
getTokenResp = requests.post(GetJwtTokenUrl, data=postBody)
logging.info("getTokenResp=%s", getTokenResp)
respJson = getTokenResp.json()
logging.info("respJson=%s", respJson)
gJwtToken = respJson["token"]
logging.info("gJwtToken=%s", gJwtToken)
if gJwtToken:
gHeaders["Authorization"] = "JWT " + gJwtToken
logging.info("gHeaders=%s", gHeaders)
def generateTopic(mysqlConn):
global gTopicDict
searchTopicLevel1Sql = """SELECT * from `keyword` WHERE type="sectorTopic" ORDER BY name"""
findTopicLevel1Ok, resultDict = mysqlConn.executeSql(searchTopicLevel1Sql)
logging.debug("%s -> %s, %s", searchTopicLevel1Sql, findTopicLevel1Ok, resultDict)
if not findTopicLevel1Ok:
logging.error("Fail to find level 1 topics")
return
topicLevel1ItemList = resultDict["data"]
for eachTopicLevel1Item in topicLevel1ItemList:
topicLevel1Id = eachTopicLevel1Item["id"]
topicLevel1Name = eachTopicLevel1Item["name"]
gTopicDict[topicLevel1Name] = {
"id": topicLevel1Id,
"children": {}
}
findRelationSql = """SELECT * from `keyword_rel` WHERE keyword1=%d""" % (topicLevel1Id)
findRelationOk, resultDict = mysqlConn.executeSql(findRelationSql)
logging.debug("%s -> %s, %s", findRelationSql, findRelationOk, resultDict)
if not findRelationOk:
logging.error("Failed to find topic level 1 and level 2 relation")
continue
level2TopicIdList = resultDict["data"]
for eachRelation in level2TopicIdList:
level2TopicId = eachRelation["keyword2"]
findTopicLevel2Sql = """SELECT * from `keyword` WHERE `id`=%d and `type`="%s" """ % (level2TopicId, "topic")
findTopicLevel2Ok, resultDict = mysqlConn.executeSql(findTopicLevel2Sql)
logging.debug("%s -> %s, %s", findTopicLevel2Sql, findTopicLevel2Ok, resultDict)
if findTopicLevel2Ok:
if resultDict["data"]:
level2Topic = resultDict["data"][0]
level2TopicName = level2Topic["name"]
gTopicDict[topicLevel1Name]["children"][level2TopicName] = {
"id": level2TopicId
}
else:
logging.error("Can not find topic id=%d", level2TopicId)
def findRealTopic(curTopic, topicList=[]):
isExisted, realTopicName = (False, "")
originTopic = curTopic
allLowcaseTopic = curTopic.lower()
capitalizedTopic = curTopic.capitalize()
titledTopic = curTopic.title()
logging.info("originTopic=%s,allLowcaseTopic=%s,capitalizedTopic=%s,titledTopic=%s",
originTopic, allLowcaseTopic, capitalizedTopic, titledTopic)
if originTopic in topicList:
isExisted = True
realTopicName = originTopic
elif allLowcaseTopic in topicList:
isExisted = True
realTopicName = allLowcaseTopic
elif capitalizedTopic in topicList:
isExisted = True
realTopicName = capitalizedTopic
elif titledTopic in topicList:
isExisted = True
realTopicName = titledTopic
else:
isExisted = False
realTopicName = ""
logging.error("Not found topic: %s", curTopic)
logging.info("topic: %s -> isExisted=%s, realTopicName=%s", curTopic, isExisted, realTopicName)
return isExisted, realTopicName
def checkTopic(curTopic, isChild=False, parentTopicName=""):
isExisted, realTopicName = (False, "")
level1TopicList = gTopicDict.keys()
if isChild and parentTopicName:
# is child topic
if parentTopicName in level1TopicList:
level1Topic = gTopicDict[parentTopicName]
childTopicDict = level1Topic["children"]
childTopicKeyList = childTopicDict.keys()
isExisted, realTopicName = findRealTopic(curTopic, childTopicKeyList)
else:
logging.error("Can not found parent topic %s for child topic %s", parentTopicName, curTopic)
else:
# is level 1=parent topic
isExisted, realTopicName = findRealTopic(curTopic, level1TopicList)
return isExisted, realTopicName
def saveScript(curScriptDict):
# {
# "place": "office 0716-1",
# "title": "title 0716-1",
# "topic": "bedtime",
# "second_level_topic": "sleepy stories",
# "age_start": 4,
# "age_end": 5,
# "operate_mark": "save",
# "dialogs": [{
# "type": "0",
# "speaker": "A",
# "content": "hello"
# }, {
# "type": "0",
# "speaker": "B",
# "content": "hi "
# }, {
# "type": "1",
# "audio_file_id": "5b21c7887f4d384d04535fe2",
# "audio_file_name": "The Tunnel.mp3"
# }]
# }
logging.debug("curScriptDict=%s", curScriptDict)
saveScriptResp = requests.post(CreateScriptUrl, headers=gHeaders, json=curScriptDict)
logging.info("saveScriptResp=%s", saveScriptResp)
if saveScriptResp.ok:
respJson = saveScriptResp.json()
logging.debug("respJson=%s", respJson)
logging.info("+++OK to create script: %s", respJson)
else:
logging.error("Fail to create script: %s", curScriptDict)
def processSingleScriptMatch(singleScriptMatch):
curScriptDict = {
"operate_mark": "save",
"place": "",
"title": "",
"age_start": -1,
"age_end": -1,
"topic": "",
"second_level_topic": "",
"dialogs": []
}
singleScript = singleScriptMatch.group("singleScript")
logging.debug("singleScript=%s", singleScript)
place = singleScriptMatch.group("place")
topic = singleScriptMatch.group("topic")
title = singleScriptMatch.group("title")
age = singleScriptMatch.group("age")
logging.debug("place=%s,topic=%s,title=%s,age=%s", place, topic, title, age)
place = place.strip()
title = title.strip()
curScriptDict["place"] = place
curScriptDict["title"] = title
topic = topic.strip()
age = age.strip()
ageMatch = re.search("(?P<ageStart>\d+)\s*-\s*(?P<ageEnd>\d+)", age)
if ageMatch:
ageStart = ageMatch.group("ageStart")
ageEnd = ageMatch.group("ageEnd")
ageStartInt = int(ageStart)
ageEndInt = int(ageEnd)
logging.debug("ageStartInt=%d,ageEndInt=%d", ageStartInt, ageEndInt)
curScriptDict["age_start"] = ageStartInt
curScriptDict["age_end"] = ageEndInt
else:
logging.error("!!! Can not recognize age format for: %s", age)
# Classroom layout-routine
# Food-vegetable
# topicMatch = re.search("(?P<topicLevel1>\w+)\s*(\-\s*(?P<topicLevel2>[\w/\s]+))?", topic)
# topicMatch = re.search("(?P<topicLevel1>[\w\s]+)\s*(\-\s*(?P<topicLevel2>[\w/\s]+))?", topic)
# topicMatch = re.search("(?P<topicLevel1>[\w\s]+)\s*([\-|-]\s*(?P<topicLevel2>[\w/\s]+))?", topic)
# sports – skiing
# topicMatch = re.search("(?P<topicLevel1>[\w\s]+)\s*([\-|-|–]\s*(?P<topicLevel2>[\w/\s]+))?", topic)
# Sports – tae-kwon-do
# topicMatch = re.search("(?P<topicLevel1>[\w\s]+)\s*([\-|-|–]\s*(?P<topicLevel2>[\w/\-\s]+))?", topic)
# Food – cakes & desserts
topicMatch = re.search("(?P<topicLevel1>[\w\s]+)\s*([\-|-|–]\s*(?P<topicLevel2>[\w/\-\&\s]+))?", topic)
if topicMatch:
topicLevel1 = topicMatch.group("topicLevel1")
topicLevel1 = topicLevel1.strip()
isExisted, realTopicLevel1 = checkTopic(topicLevel1)
if isExisted:
curScriptDict["topic"] = realTopicLevel1
topicLevel2 = topicMatch.group("topicLevel2")
if topicLevel2:
topicLevel2 = topicLevel2.strip()
isExisted, realTopicLevel2 = checkTopic(topicLevel2, isChild=True, parentTopicName=realTopicLevel1)
if isExisted:
curScriptDict["second_level_topic"] = realTopicLevel2
else:
logging.error("Can not find real child topic %s from parent %s", topicLevel2, realTopicLevel1)
else:
logging.warning("Not found topic level 2 from topic string: %s" % topic)
else:
logging.error("Can not find level1 topic: %s", topicLevel1)
else:
logging.error("!!! Can not recognize topic format for: %s" % topic)
content = singleScriptMatch.group("content")
logging.debug("content=%s", content)
singleDialogPattern = r"(?P<speaker>\w+):\s*(?P<sentence>[^\n]+)\n"
singleDialogMatchIterator = re.finditer(singleDialogPattern, content, flags=re.I | re.M | re.S)
for dialogIdx, eachDialog in enumerate(singleDialogMatchIterator):
dialogNum = dialogIdx + 1
logging.debug("[%d] eachDialog=%s", dialogNum, eachDialog)
speaker = eachDialog.group("speaker")
logging.debug("speaker=%s", speaker)
sentence = eachDialog.group("sentence")
logging.debug("sentence=%s", sentence)
DialogTypeText = "0"
# DialogTypeAudio = "1"
curDialog = {
"type": DialogTypeText,
"speaker": speaker,
"content": sentence
}
curScriptDict["dialogs"].append(curDialog)
logging.info("[%d] curScriptDict=%s", scriptNum, curScriptDict)
saveScript(curScriptDict)
################################################################################
# Main
################################################################################
# init logging
logFilename = crifanFile.getInputFileBasenameNoSuffix() + ".log"
crifanLogging.loggingInit(logFilename)
logging.info("Logging initialized to %s", logFilename)
mysqlConn = crifanMysql.MysqlDb(config=MysqlConfigDict)
logging.info("mysqlConn=%s", mysqlConn)
generateTopic(mysqlConn)
logging.info("gTopicDict=%s", gTopicDict)
curPath = os.getcwd()
for eachFilename in ScriptFilenameList:
eachFullFilePath = os.path.join(curPath, ScriptFolder, eachFilename)
logging.info("eachFullFilePath=%s", eachFullFilePath)
singleScriptPattern = ""
if eachFilename == "person_1.txt":
singleScriptPattern = r"(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n(?P<content>.+?\n))\n+"
updateTokenAndHeader(UserInfoDict["wuman"])
elif eachFilename == "person_2.txt":
singleScriptPattern = r"(?P<singleScript>topic:(?P<topic>[^\n]+)\nplace:(?P<place>[^\n]+)\nage:(?P<age>[^\n]+)\ntitle:(?P<title>[^\n]+)\n(?P<content>.+?\n))\n+"
updateTokenAndHeader(UserInfoDict["zhouyue"])
with open(eachFullFilePath, "r") as fp:
allLine = fp.read()
# print("allLine=%s" % allLine)
allScriptMatchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.S)
logging.info("allScriptMatchIterator=%s", allScriptMatchIterator)
# if allScriptMatchIterator:
for scriptIdx, curScriptMatch in enumerate(allScriptMatchIterator):
scriptNum = scriptIdx + 1
logging.info("[%d] curScriptMatch=%s", scriptNum, curScriptMatch)
processSingleScriptMatch(curScriptMatch)
处理了:
Place: School canteen
Topic: food
Tittle:Have lunch
Age: 3-4
J: What did you have for lunch?
L: I ate rice, fish and bread.
J: Do you like rice?
L: Yes, I do.
J: Do you like fish?
L: Yes, I do.
J: Do you like bread?
L: No, I don’t.
J: What did you drink?
L: I drank milk.
J: Do you like milk?
L: Yes, I do.
Place: home
Topic: house
Tittle: Doing housework
Age: 4-5
J: Do you like cooking, mom?
M: Yes, I do a lot. What about you?
J: Mom, you know me. I can’t cook.
M: But can you help me wash dishes?
J: Yes, I can help you.
M: Let’s make a deal, ok?
J: What kind of deal?
M: I’m going to cook.
J: And then?
M: Then you wash the dishes after the meal.
J: That’s ok. I’ d like to help you mom.
M: You are a good boy.
和:
topic: Health – illness
Place: home
Age: 4-5
title: have a headache
A: Bob, I’m not feeling good.
B: What’s wrong?
A: I’ve got a headache.
B: Oh, take some medicine, honey. Let me get some for you.
A: Thanks, Bob.
topic: House – kitchen
Place: home
Age: 6-7
title: feeling hungry
A: Hey, Bob, what are you doing here?
B: I’m hungry. I’m looking for some food.
A: We still have some vegetables in the refrigerator. I can make you a simple salad.
B: Great! Thank you!
A: What kind of dressing do you want?
B: French dressing is fine.
最后保存到CMS系统中了:
转载请注明:在路上 » 【已解决】把文本格式的剧本内容用Python批量导入后台系统