折腾:
【暂时解决】给PySpider中用科学上网的代理打开需要翻墙的页面
期间,调试PySpider发现打开页面,出现很多错误,其中有304:
1 2 3 4 | console: AT: [getOffer()] request failed [object Object]console: AT: Rendering : failed target-global-mbox error timeout[304] https://www.scholastic.com/teachers/bookwizard/ 20.146[I 181010 15:46:44 tornado_fetcher:520] [304] ScholasticStorybook:34b1c45f09fa84805dd1697c1809e8c9 https://www.scholastic.com/teachers/bookwizard/ 20.15s |
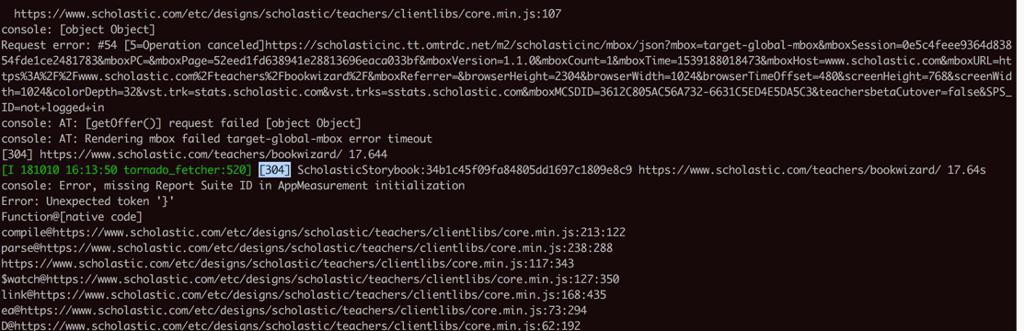
PySpider http 304
加上:
force_update=True,
试试,现象依旧:
1 2 3 | [I 181010 16:02:23 tornado_fetcher:520] [304] ScholasticStorybook:34b1c45f09fa84805dd1697c1809e8c9 https://www.scholastic.com/teachers/bookwizard/ 20.02s |
关键还是不返回数据
试试:
1 2 3 4 5 | crawl_config = { 'force_update': True, 'last_modified': False, 'etag': False} |
问题依旧。
还是去官网详细了解这几个参数的含义:
“etag
“last_modified
“force_update
force update task params even if the task is in ACTIVE status.”
pyspider 304
“I must create a new project like before to run it again, then the 304 problem is gone.
If you don’t want this feature, set etag and last_modified to False in self.crawl.”
结果此处虽然设置了:
1 2 3 4 5 6 7 8 9 10 | crawl_config = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36", # "proxy": "127.0.0.1:10870", # "proxy": "127.0.0.1:1087", # "proxy": "localhost:1087", 'force_update': True, 'last_modified': False, 'etag': False } |
但是结果竟然还是:
返回为空
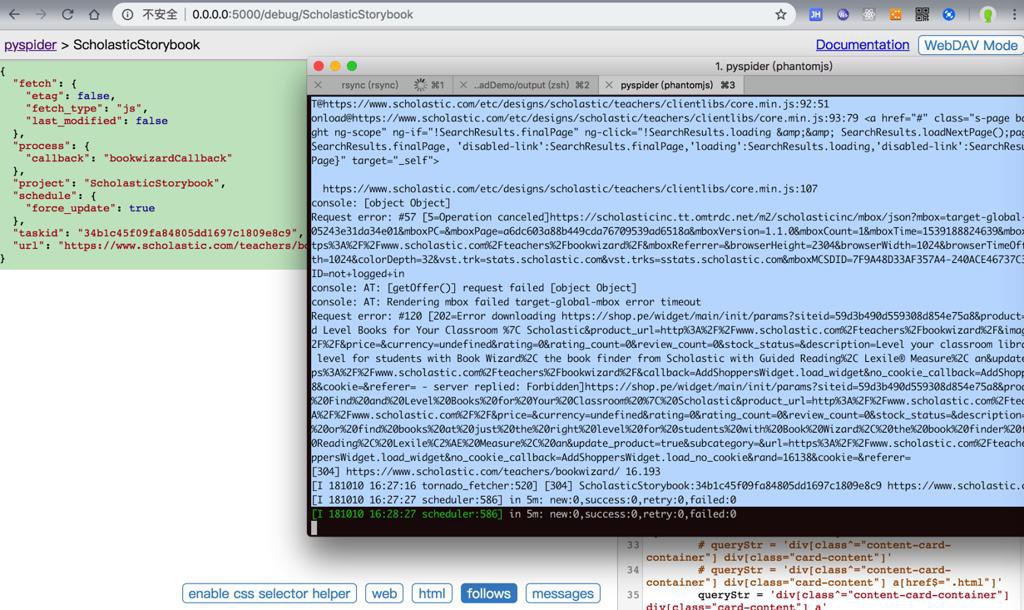
然后不关闭页面,再次运行的话,就可以正常加载内容了:
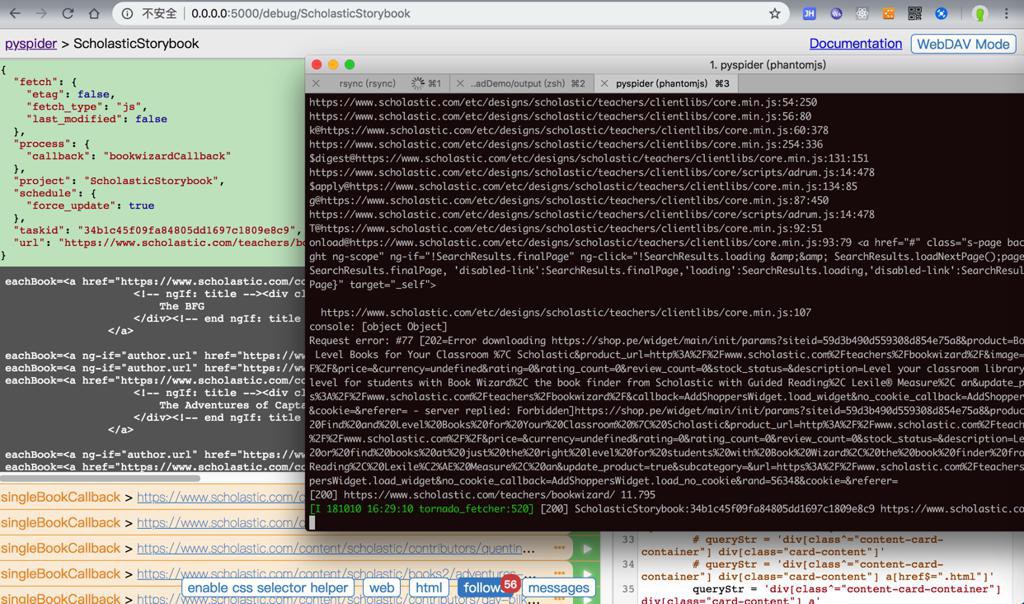
再次运行又304
再去运行也还是304
怀疑可能是phantomjs的问题?
去停掉PySpider 重新开启:
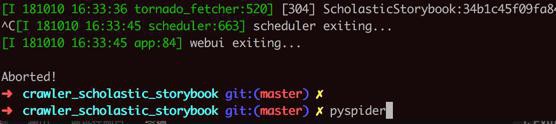
看看是否一定可以200,而不是304
然后发现果然是的:
每次重启PySpider后,的确可以保证此处的:
(虽然内部部分js有错误)
但是页面可以正常加载,是200
-》看来就是phantomjs方面的问题?
-》或者说是和前面几个参数:
force_update,last_modified,etag
有关系。
所以此处是:
- 每次重启PySpider的话,可以避免304
- 但是后续在WebUI中调试,再次Run,还是会经常遇到304
- 如果只是考虑到此处的需求:调试代码时,确保第一次运行不会304,后续正在开始运行时,就不会有问题
- 则可以暂时不继续深究了
- 但是为了想要搞清楚到底如何才能避免此问题,还是继续看看,能否彻底解决
pyspider avoid 304
没有完全看懂,大概意思是:Spec和Chrome,Firefox等不同浏览器,做法都不太一样
但是都是根据spec来的。
感觉此处有304,估计是用了fetch_type=”js”,导致js部分用了phantomjs
然后其内部估计用了缓存,导致此处的304?
【总结】
此处,在WebUI中调试时,对于:
最开始是200
之后再去Run,就是304了。
对此,暂时还是没有找到彻底的解决304的办法。
不过发现:重启PySpider,此处不会304
-》基本满足了此处调试和后续正式运行时,确保是200,算是暂时避免了304的问题。
转载请注明:在路上 » 【基本解决】PySpider打开页面出现304