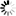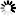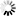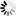通过上一节的例子,可以看到“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
在Windows平台下,有一个最简单的转化方法,就是使用内置的记事本小程序Notepad.exe。打开文件后,点击"文件"→"另存为"会跳出一个对话框,在最底部有一个"编码"的下拉条:

里面有四个选项:ANSI,Unicode,Unicode big Endian 和 UTF-8:
- ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。
- Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的Little Endian格式
- Unicode Big Endian编码与上一个选项相对应
关于Little Endian和Big Endian,可以参考大端(Big Endian)与小端(Little Endian)详解
- UTF-8编码,也就是上一节谈到的编码方法
选择完”编码方式“后,点击”保存“按钮,文件的编码方式就立刻转换好了。
下面,举一个实例:
打开”记事本“程序Notepad.exe,新建一个文本文件,内容就是一个”严“字,依次采用ANSI,Unicode,Unicode big Endian 和 UTF-8编码方式保存。
然后,用文本编辑软件UltraEdit的”十六进制功能“,观察该文件的内部编码方式。
- ANSI
文件的编码就是两个字节“D1 CF”,这正是“严”的GB2312编码,这也暗示GB2312是采用大头方式存储的
- Unicode
编码是四个字节“FF FE 25 4E”,其中“FF FE”表明是小头方式存储,真正的编码是4E25。
- Unicode big Endian
编码是四个字节“FE FF 4E 25”,其中“FE FF”表明是大头方式存储。
- UTF-8
编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的
对于UTF-8的BOM(Byte Order Mark),即“EF BB BF”,是对于UTF-8编码,微软自己添加的,由此,会导致和其他很多软件等不兼容。而Unicode标准中,也不推荐此给UTF-8添加“EF BB BF”的BOM。
刚去测试了一下,在Window XP中,将中文汉字“严”在记事本中另存为UTF-8之后,用Notepad++去查看其十六进制的值,的确是“EF BB BF E4 B8 A5”,然后手动删除了“EF BB BF”的BOM,保存后,再去用记事本打开,发现没了BOM的UTF-8,记事本也是可以正确显示出“严”字的。所以,结论是:
- 给UTF-8加“EF BB BF”的BOM,是微软自己的做法,即微软发现编码是UTF-8的话,会给文件最开始加上“EF BB BF”
- Unicode的官方标准,不推荐这种做法,即不推荐给UTF-8加“EF BB BF”的BOM
- 所以,其他人写软件处理文字编码的话,最好不要给UTF-8加BOM。当然,如果你非得要兼容微软的做法,那么去解析不同编码的文件的话,针对UTF-8编码,就要考虑这个特殊的的BOM了
更多关于BOM的解释,参见第 2.7 节 “BOM”
 |  |  |
| 2.4.3.1. UTF-8 |  | 2.5. 代码页Code Page |